- Ngrinder로 성능을 테스트 후 캐시로 성능 올리기2021년 10월 06일 14시 07분 36초에 업로드 된 글입니다.작성자: jCurve728x90반응형
요즘 진행하고 있는 토이 프로젝트에서 어느정도 API 구현이 끝난 후 "현재 이 서버가 얼마나 많은 부하를 감당할 수 있을까?" 라는 생각이 들었습니다.
그래서 성능을 테스트하고자 네이버 오픈소스 프로젝트인 nGrinder를 사용하여 서버에 부하를 걸고 테스트를 해보았습니다.
(http://naver.github.io/ngrinder/)
테스트로 선택한 API는 현재 서버에서 가장 비용이 비싸다고 생각되는 API(한 트랜잭션안에 제일 많은 조인 쿼리와 실제 나가는 쿼리 수가 많음)를 선택하여 성능을 테스트 하였고 이후 성능 개선을 위해 캐시를 적용했습니다.
이러한 테스트는 여러개의 서버를 두고 해야 정확한 테스트가 가능하지만 제가 가진 서버는 오직 제 컴퓨터 한 대와 이미 사용중인 EC2 한 대 이므로 모든 테스트는 한 대에서 이루어졌고 서버 자원 할당이 많이 떨어져 성능이 더 낮게 나올 것이라는거 미리 말씀드립니다.
먼저 진행중인 프로젝트의 구성은 스프링 서버 1대 , 개발용 H2 데이터베이스 , Docker에 띄운 Redis 컨테이너 1대, 모니터링을 위해 동작중인 Docker Pin-Point 구성 컨테이너 여러대, Docker nGrinder Agent, Docker nGrinder Controller 이렇게 입니다. (물리 서버 한 대에 구성이 좀 많죠,,?)

Redis의 사용 용도는 추후 로드밸런싱을 해서 배포 예정인데 그때를 위한 세션 저장용으로 구성해 두었습니다.
다시한번 말씀드리자면 성능 테스트를 하기 위해서는 위의 구성을 각각의 EC2로 나누어 물리 자원을 따로 할당 받도록 하는 것이 좋습니다.
(저는 AWS 프리티어라 비용문제로 여러대 못 돌려서 Docker띄워서 컴퓨터 한대로 돌리는거에요)
nGrinder는 Controller와 Agent로 구성이 되는데
Agent는 Controller의 명령을 받고 부하를 발생시키고 Controller는 부하 발생을 위한 스크립트 작성 및 성능테스트 모니터링 및 테스트 결과 확인, Agent관리등의 일을 하게 됩니다.
제대로된 성능 테스트라면 Controller용 서버 한 대와 Agent로 설정할 서버 여러대를 따로 가져가서 테스트 대상 서버인 Target 서버의 부하를 발생시키게 됩니다.
현재 저의 컴퓨터는 Ubuntu 20.04를 사용중이므로 localhost로 부하 발생을 보내기 위해 방화벽을 꺼주고 시작하겠습니다.
먼저 Spring을 동작 시키고 앞서 Docker로 실행시켜 동작중인 nGrinder Controller 접속 포트로 접속을 합니다.
nGrinder에서 localhost:8080에서 동작중인 Spring 서버의 비용이 가장 큰 API로 부하를 보내는 스크립트를 작성합니다.
(스크립트 작성과 검증, nGrinder 구성은 더 좋은 블로그 글이 많이 있으므로 여기선 제외 하겠습니다.)
Agent한대로 3000명 -> 1000명 -> 300명 -> 100명으로 부하 범위를 나누어 측정하고 각각의 TPS와 Latency를
측정해 보았습니다.
일단 3000명은 cpu 사용률이 최대치에 lack of free memory 메시지를 주며 에러가 났습니다.

가상 유저 1000명 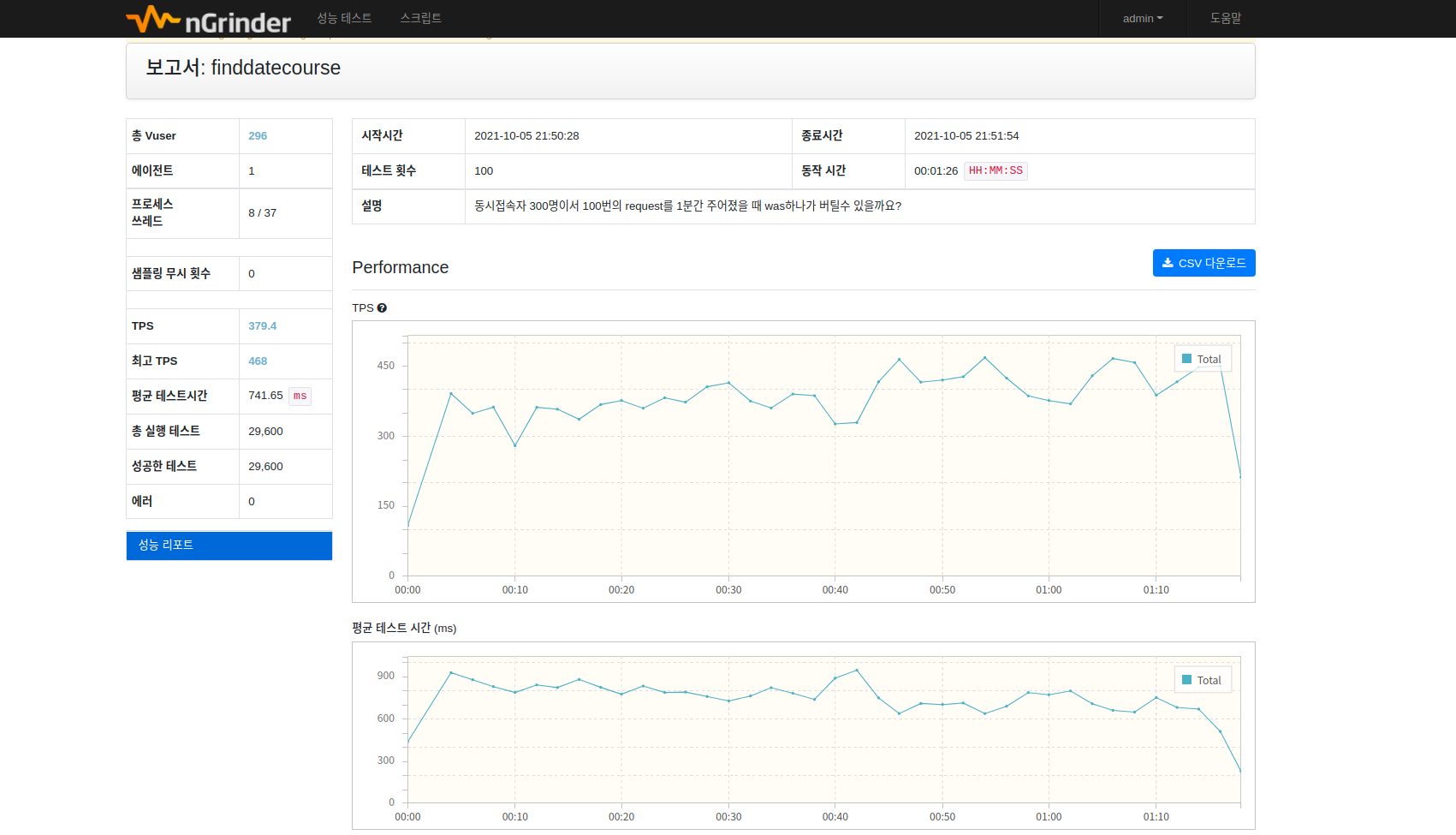
가상유저 300명 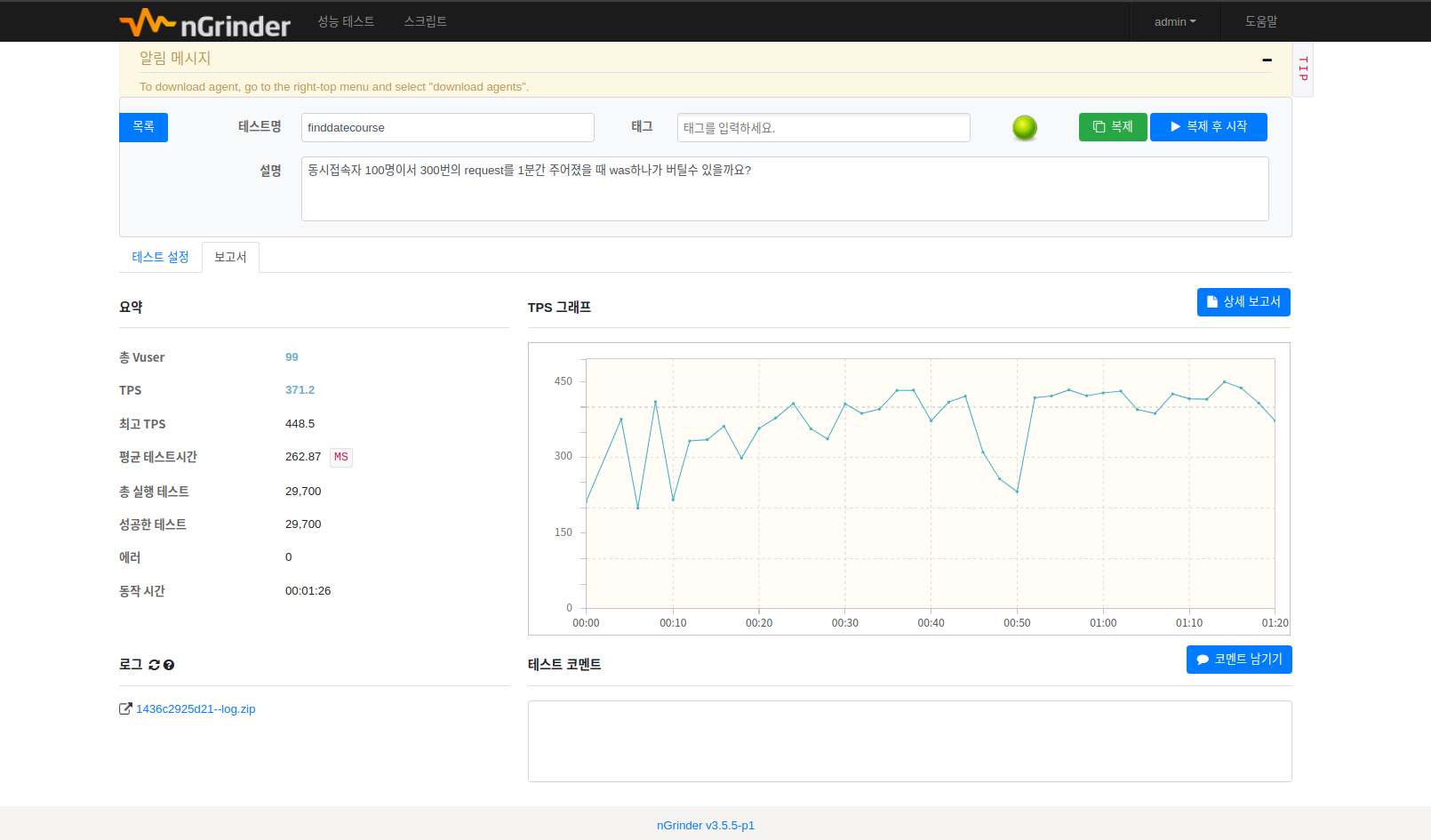
가상유저 100명 TPS의 경우 조건을 달리해서 3,4번 더 해보았는데 평균적으로 350정도가 나오는데 latency는 부하를 더 줄 수록 더 높게 나왔다.
역시 한대의 자원을 여러 프로세스가 나눠 갖다 보니 TPS가 낮게 나올 수 밖에 없는데 어느부분에서 시간을 제일 많이 잡아 먹는지 확인하기 위해 PinPoint로 해당 부하 시점을 전체 선택 후 가장 병목이 큰 지점을 찾아 보았다.

위 사진을 보면 HikariCP 커넥션 풀에서 커넥션을 받아오는 부분에서 가장 높은 ms를 차지하고 있다.
근데 이 성능 테스트를 진행한 API의 경우 연산에 드는 비용이 API들 중에서 제일 크지만 화면단을 구성하기 위한 API중 하나이고
화면 구성의 경우 약간의 시간차가 있더라도 새로운 정보를 조금 늦게 보여주어도 괜찮다는 비즈니스 결정 가정하에
성능 개선에 여러 선택지가 있겠지만 위에서는 Connection을 받는 부분에서 가장 많은 ms를 잡아 먹기 때문에 캐시를 통해 해당 API의 Service 메서드를 실행시키지 않고 이미 메모리에 캐싱해둔 데이터를 반환하는 것으로 성능 개선이 가능하다고 생각다고 생각했습니다.
그래서 spring boot starter cache를 사용해서 간단하게 캐싱을 적용하고 다시 테스트를 돌려겠습니다.


캐시를 적용한 후 nGrinder도 다시 테스트를 돌렸을때 TPS가 3배 가까이 높아진 것을 볼 수 있습니다.

PinPoint로 다시 해당 부하 테스트를 선택하여 본 결과 아까와 같이 HikariCP를 따로 건들지 않고 Spring 서버 내부에 저장된 캐시를 사용하므로 ms 차이가 확연히 줄어든 것을 볼 수 있습니다.
이렇게 자주 사용되지만 쉽게 바뀌지 않는 데이터라면 캐싱을 해서 성능 향상을 고려할 수 있지만,
캐시 할 수 없는 상황이라면 현재 실행한 쿼리는 실행계획을 통해 index를 타는 것을 볼 수 있었지만 역정규화나 혹은 slave DB를 늘리거나 커넥션 풀 사이즈를 DB 성능에 맞춰 조절하는 방법도 있습니다.
참고로 저는 여기서 HikariCP connection pool size default(10) 로 사용했습니다. Docker Container가 너무 여러개 올라가서 딱 몇개로 정해야 할지 애매해서 default로 두고 사용했습니다.
이렇게 오늘은 nGrinder를 사용해서 부하 테스트를 해보았는데요 물리 서버 한대에서도 캐시를 사용했을 때 성능차이가 3배 가까이 향상되는 것을 보면 실제로 여러개의 EC2 인스턴스를 가지고 테스트 했다면 더 높은 TPS를 보여 드릴 수 있었을 것 같네요
그럼 20000
 반응형
반응형'DEV-OPS' 카테고리의 다른 글
Docker Nginx - Reverse Proxy, Load Balancing (0) 2021.11.27 Docker-Compose로 반복 컨테이너 작업 줄이기 (0) 2021.11.27 Jenkins CI/CD Pipeline (0) 2021.11.25 댓글