- JPA 반복문 쿼리 vs Batch Insert2021년 10월 10일 20시 52분 25초에 업로드 된 글입니다.작성자: jCurve728x90반응형
전에 프로젝트를 진행하며 for문을 돌며 query를 날려야했던 상황이 있었는데 그때 공부했던 내용을 정리해 보겠습니다.
우선 문제 상황은 하나의 course에는 여러개의 location과 hash-tag를 가지고 있고 사용자가 등록하고자 하는 course를 요청에서 받아 location과 hash-tag를 등록하는 상황이었습니다.
이때 저는 반복문을 돌며 쿼리를 수행하는게 매번 반복문을 돌때마다 db와 네트워크를 n번 만큼 타야하기 때문에 성능적으로 저하가 있을 것 같다고 생각을 하게 되었고 결과적으로 JPA의 save로 단건 저장하던 쿼리를 saveAll로 여러건 묶어서 보내는 것이 성능이 더 좋게 나온다는 테스트 결과를 가지고 코드를 작성했습니다.
이 과정에서 save를 사용하든 saveAll을 사용하든 hibernate sql 로그를 보면 똑같이 insert 쿼리가 여러번 나가게 되어 처음에는 제대로 동작하지 않는 것으로 착각을 하게 되었습니다.
기존의 예상했던 쿼리가 커밋되는 모습은
insert into course (id,location_name,posX,posY,text,photo_url) values ('1','location_name1','123','26','s3@ddddd'), ('2','location_name1','123','26','s3@ddddd'), ('3','location_name1','123','26','s3@ddddd'), ('4','location_name1','123','26','s3@ddddd'), ('5','location_name1','123','26','s3@ddddd'), ('6','location_name1','123','26','s3@ddddd'), ('7','location_name1','123','26','s3@ddddd'), ('8','location_name1','123','26','s3@ddddd');이런식의 모습을 생각했지만 사실은 그게 아니었습니다.

JPA 구현체로 하이버네이트를 사용하고 있는데 하이터네이트가 제공하는 batch insert는 위에서 작성한 쿼리처럼 multi low로 만들어 제공하는 방식이 아니라 여러 쿼리를 모아 한번에 보내는 방식이었습니다.
그래서 쿼리 문장이 변하지는 않지만 테스트 시간 측정시 성능적인 이점을 확인할 수 있었던 겁니다.
batch insert를 위한 설정으로는

위 사진 처럼 설정하게되면 동작하는데
각각의 속성의 설명을 하자면 우선 order_inserts, order_updates입니다.
이 값은 예를들어 쿼리가
insert into course (id,location_name,posX,posY,text,photo_url) values ('1','location_name1','123','26','s3@ddddd'); insert into hash_tag (id,tagName) vlaues (`1`,`#test`); insert into course (id,location_name,posX,posY,text,photo_url) values ('2','location_name1','123','26','s3@ddddd'); insert into hash_tag (id,tagName) vlaues (`2`,`#test`); insert into course (id,location_name,posX,posY,text,photo_url) values ('3','location_name1','123','26','s3@ddddd'); insert into hash_tag (id,tagName) vlaues (`3`,`#test`); insert into course (id,location_name,posX,posY,text,photo_url) values ('4','location_name1','123','26','s3@ddddd'); insert into hash_tag (id,tagName) vlaues (`4`,`#test`);이런식으로 번갈아 실행되게 되면 batch insert를 실행시킬 수 없는데
이를 order 속성에 true값을 세팅해주면 실제 커밋시에
insert into course (id,location_name,posX,posY,text,photo_url) values ('1','location_name1','123','26','s3@ddddd'); insert into course (id,location_name,posX,posY,text,photo_url) values ('2','location_name1','123','26','s3@ddddd'); insert into course (id,location_name,posX,posY,text,photo_url) values ('3','location_name1','123','26','s3@ddddd'); insert into course (id,location_name,posX,posY,text,photo_url) values ('4','location_name1','123','26','s3@ddddd'); insert into hash_tag (id,tagName) vlaues (`1`,`#test`); insert into hash_tag (id,tagName) vlaues (`2`,`#test`); insert into hash_tag (id,tagName) vlaues (`3`,`#test`); insert into hash_tag (id,tagName) vlaues (`4`,`#test`);이런식으로 정렬하여 batch insert가 가능하도록 동작합니다.
그리고 batch insert시 버퍼 크기를 얼마나 크게 잡을지 설정하는 값으로 `hibernate.jdbc.batch_size` 속성을 사용하게 됩니다.
rewriteBatchedStatements속성은 하이버네이트에서 multi-row를 지원하지 않기 때문에 이 속성 값을 true로 설정해서 database connector에서 넘어온 insert 구문을 재작성하여 multi-row로 만들어 줍니다.
추가적으로 JPA에서 batch insert시에 주의해야할 부분이 있는데 Entity 선언시에 id 생성 전략을 IDENTITY로 설정하게 되면 실제 엔티티 생성시에 커밋을 날리고 id 값을 DB에서 설정해주는 형태 이므로 IDENTITY로 설정된 Entity의 batch insert 시점에는 id값이 없기 때문에 batch insert가 불가능합니다.
그래서 Sequence 전략이나 Table 전략을 사용해서 id 채번을 하고 batch insert하는 방식으로 변경해서 진행해야 합니다.
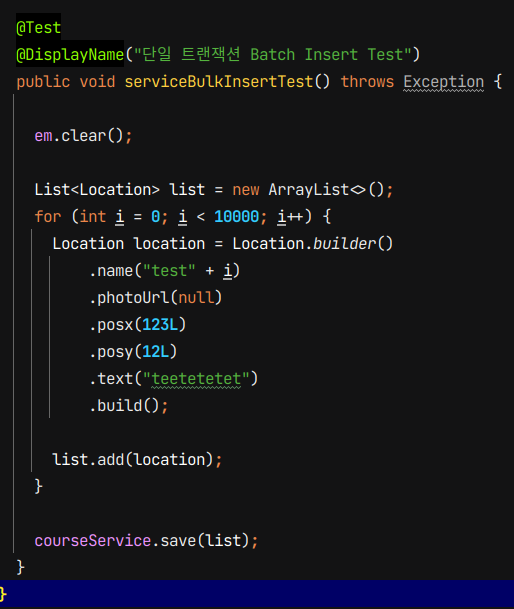
이제 실제 테스트 결과와 코드를 보자면
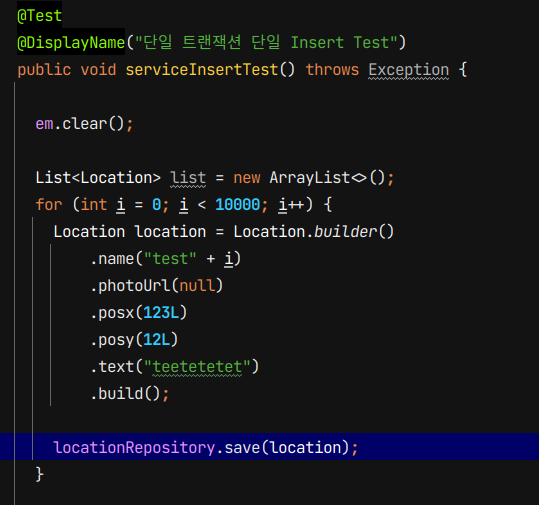
첫 번째 테스트는 각각의 location을 반복문을 돌며 단건씩 insert하는 테스트 이고
두 번째 테스트는 모든 location을 모아 list로 batch insert하는 테스트 입니다.
이 결과

대략 10배 가량의 속도 차이로 batch insert의 수행시간이 훨씬 짧은 것을 확인할 수 있습니다.
반응형'Spring' 카테고리의 다른 글
Read Write Query 분리 (0) 2021.11.28 Spring Swagger - API 문서화 (0) 2021.10.11 Spring Session Redis (0) 2021.10.09 Spring HandleMethodArgumentResolver로 반복적인 Session 연산 처리 (0) 2021.10.08 Spring 로깅 log4j2 (0) 2021.10.07 댓글